")
Forschungsbereich für angewandte Statistik und Datenwissenschaften
Die Arbeitsgruppe befasst sich mit der Anwendung von Methoden der Statistik sowie der Modellierung von Problemen der kombinatorischen Optimierung und Datenanalyse auf wirtschaftliche und technische Fragestellungen. Die vielseitige Anwendbarkeit dieser Modelle wird dokumentiert durch eine Vielzahl in der Vergangenheit durchgeführter Verbundprojekte und betreuter Abschlussarbeiten aus verschiedenen Bereichen wie der Anonymisierung georeferenzierter mobiler Fahrzeugdaten, der multivariaten Analyse von Industriedaten, der optimalen Standortplanung, der Ablaufplanung in der Fertigung, der optimalen Tourenplanung, der Transportkostenminimierung, der optimalen Schichteinteilung, des analytischen Vergleichs verschiedener Kommissionierprobleme, des Einsatzes von Werkzeugen des Six Sigma und von Methoden der statistischen Versuchsplanung, des Umweltcontrollings im Fertigungsprozess, der Bewertung des Einflusses moderner hybrider Lehrmethoden auf den Lernerfolg u.v.m..
Bei der Problemlösung kommen neben effizienten Algorithmen der künstlichen Intelligenz auch Algorithmen aus Spezialdisziplinen der diskreten Mathematik, Numerik und Statistik zum Einsatz, darunter die Optimierung unter Nebenbedingungen, Systemtheorie, Datenbanktechnologie, Statistische Lebensdaueranalyse, Spieltheorie, Graphentheorie und Kombinatorik, Entscheidungstheorie und Kosten-Nutzen-Analysen.
Unsere Aufgaben umfassen neben der Forschung und Lehre auch das Angebot an spezialisierten Schulungen und die Erstellung von Gutachten und Machbarkeitsstudien für Unternehmen. Wir unterstützen Anwender aus den Ingenieurs-, Wirtschafts- und Lebenswissenschaften bei der Problemlösung, wobei wir auf eine langjährige Erfahrung in der Auftragsforschung und Durchführung von Projekten mit Partnern aus dem Hochschulbereich, der Industrie und regionalen Unternehmen bauen können. Zur Lösung aktueller Problemstellungen werden neben Projektmitarbeitern auch Studierende im Rahmen einer Studien- oder Abschlussarbeit eingesetzt.
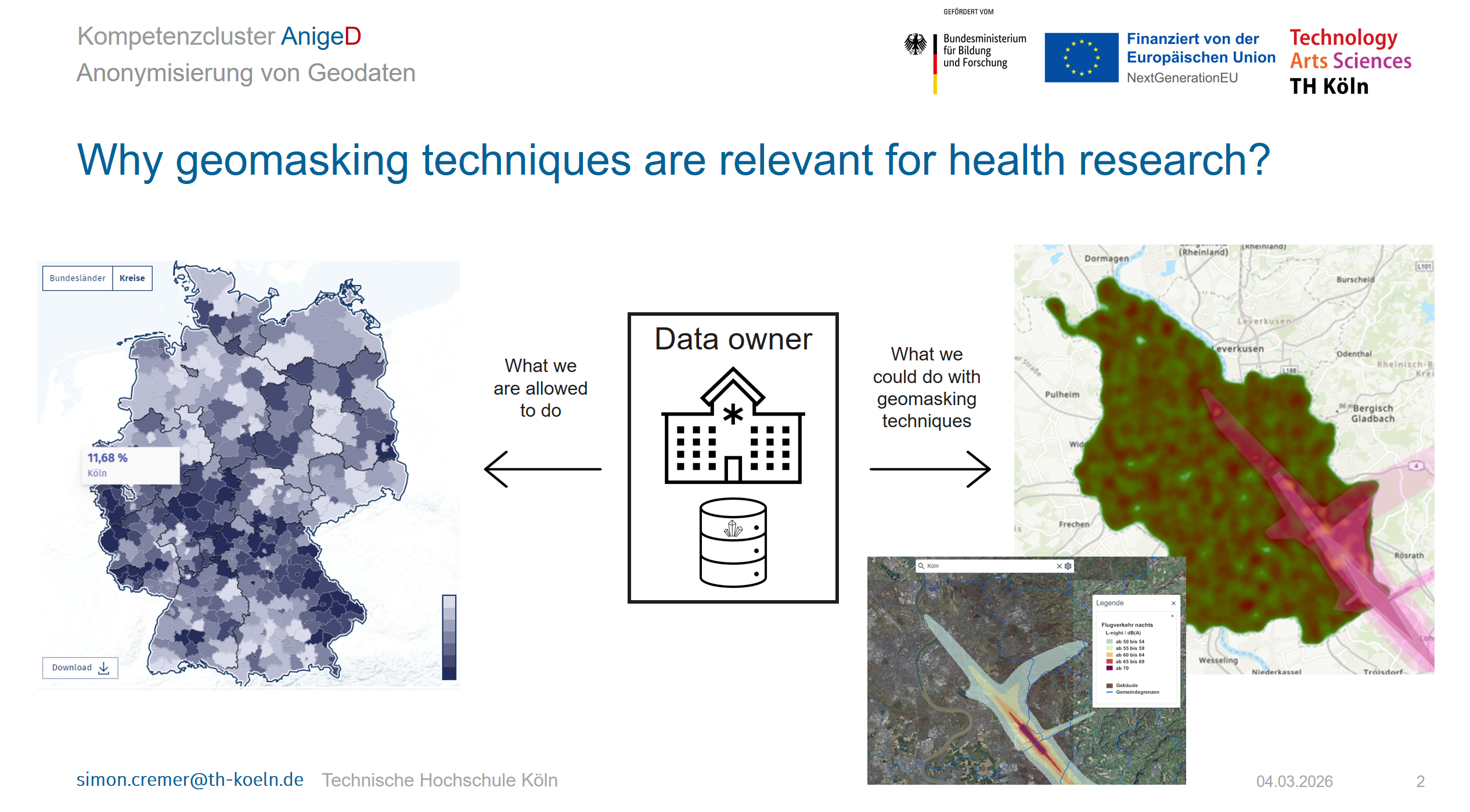
Ein besonderer Forschungsschwerpunkt liegt in der statistischen Geheimhaltung und Anonymisierung von vertraulichen Einzeldaten, sogenannten Mikrodaten. Die praktikable und wirkungsvolle Umsetzung bestehender Datenschutzgesetze, insbesondere der Datenschutzgrundverordnung (DSGVO), stellt unsere Gesellschaft vor sehr große Herausforderungen. Daher sehen wir uns verpflichtet, regelmäßig Forschungsprojekte in diesem Bereich durchzuführen sowie Spezialseminare und Schulungen anzubieten, die auf die Sensibilisierung der Teilnehmer für aktuelle Anforderungen des Datenschutzes abstellen. Zwecks statistischer Analyse von Forschungsdaten ist eine entsprechende Expertise in der Datenanonymisierung zur Generierung solcher Datenschätze essentiell. Durch die Mitwirkung in zahlreichen Forschungsprojekten seit über 25 Jahren hat sich ein methodischer Werkzeugkasten gefüllt und ein internationales Netzwerk von Hochschulen im In- und Ausland, nationalen Statistikämtern und dem europäischen Statistikamt Eurostat gebildet. Ein erst kürzlich erfolgreich abgeschlossenes EU-Projekt beschäftigte sich mit der Anonymisierung von Punktdaten bzw. Mikrodaten mit direktem Regionalbezug. Speziell die Anonymisierung von Gesundheitsdaten stellt aufgrund des hohen Grades an Individualität der Auskunftgebenden eine große Herausforderung dar. Diese Daten gelten laut DSGVO (Art. 9) als besonders sensibel und schutzwürdig. Zur Identifikation vertraulicher Information kann ein potenzieller Datenangreifer die Geokoordinaten der Meldeadressen etwa aus Patientendaten nutzen. Aber nicht nur Zahlentabellen, sondern auch Merkmale wie Bilddaten (Röntgen, CT-Scans), behandelnder Arzt oder verabreichte Medikamente können zur Identifikation von Individuen beitragen, sogenannte „Health-Apps“ sammeln reichlich Daten über den Gesundheitszustand der Nutzer. Eine Zusammenarbeit mit Datenhaltern aus dem öffentlichen und privaten Bereich ist daher wichtig für die erfolgreiche Anwendung und kontinuierliche Weiterentwicklung der Anonymisierungsmethodik. Die TH Köln ist aus diesem Grunde Partner eines ebenfalls durch die EU und das BMFTR geförderten Kompetenzclusters AnigeD, welches in Zusammenarbeit mit verschiedenen Datenhaltern und einer Reihe universitärer Partner betrieben wird.
In der Lehre sind wir verantwortlich für die Statistik-Grundausbildung von Studierenden der Fakultät und bieten im Wahlbereich Bachelor und Master verschiedene Module zur multivariaten Datenanalyse, kombinatorischen Optimierung und statistischen Geheimhaltung an. Studierende aller Fachrichtungen mit Affinität zu Mathematik, Statistik oder Informatik sind eingeladen, eine Abschluss- oder Projektarbeit im Kontext eines aktuellen Forschungsprojektes zu schreiben bzw. als studentische/ wissenschaftliche Hilfskraft in Projekten oder als Tutoren in Lehrveranstaltungen mitzuwirken.
Bildergalerie
 0 / 0
0 / 0
Anonymisierung von Geodaten (Bild: TH Köln)
 0 / 0
0 / 0
Prof. Rainer Lenz beim 34. Wissenschaftlichen Kolloquium "Anonymität bei integrierten und georeferenzierten Daten (AnigeD)" in Wiesbaden (Bild: Uwe Voelkner)
 0 / 0
0 / 0
Simon Cremer beim 34. Wissenschaftlichen Kolloquium "Anonymität bei integrierten und georeferenzierten Daten (AnigeD)" in Wiesbaden (Bild: Uwe Voelkner)